Machine Learning: O que é e Como Funciona?


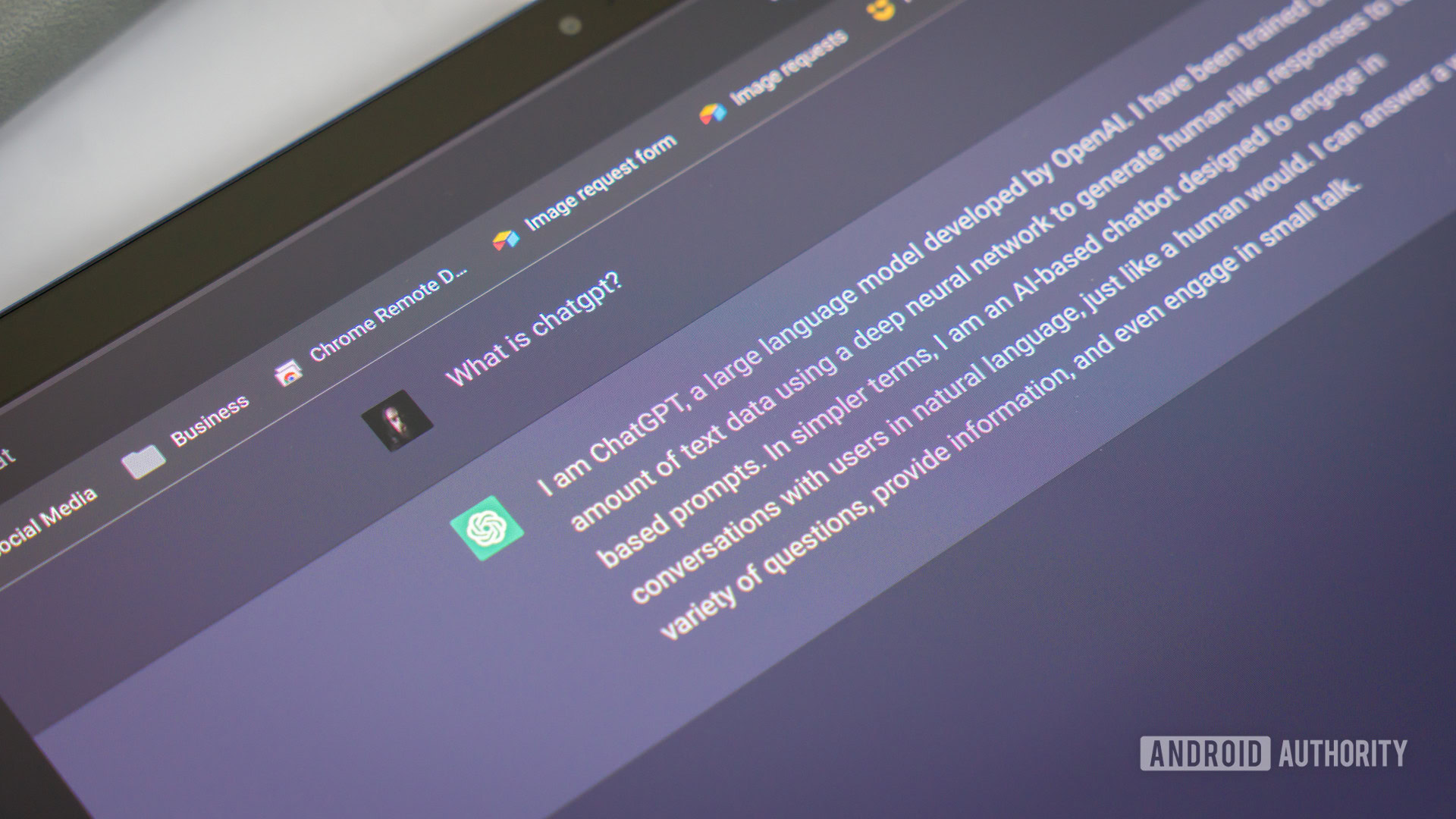
Desde chatbots como ChatGPT e Google Bard até recomendações em sites como Amazon e YouTube, o aprendizado de máquina influencia quase todos os aspectos de nossas vidas diárias.
O aprendizado de máquina (machine learning) é um subconjunto da inteligência artificial que permite que os computadores aprendam com suas próprias experiências – da mesma forma que fazemos quando adquirimos uma nova habilidade. Quando implementada corretamente, a tecnologia pode realizar algumas tarefas melhor do que qualquer ser humano, e muitas vezes em segundos.
Com o quão comum o aprendizado de máquina se tornou hoje, você pode se perguntar como ele funciona e quais são suas limitações. Então aqui está uma introdução simples sobre a tecnologia. Não se preocupe se você não tem formação em ciência da computação – este artigo é uma visão geral de alto nível do que acontece nos bastidores.
Leia também: Quais são os Melhores Telefones Baratos? Testamos 44, aqui estão nossos 8 melhores
O que é aprendizado de máquina (machine learning)?

Embora muitas pessoas usem os termos machine learning(ML) e inteligência artificial (IA) de forma intercambiável, na verdade há uma diferença entre os dois.
As primeiras aplicações da IA, teorizadas há cerca de 50 anos, eram extremamente básicas para os padrões atuais. Um jogo de xadrez onde você joga contra adversários controlados pelo computador, por exemplo, já poderia ser considerado revolucionário. É fácil perceber porquê – afinal, a capacidade de resolver problemas com base num conjunto de regras pode ser qualificada como “inteligência” básica. Hoje em dia, porém, consideraríamos tal sistema extremamente rudimentar, pois carece de experiência – um componente-chave da inteligência humana. É aqui que entra o aprendizado de máquina.
O machine learnine permite que os computadores aprendam ou treinem a partir de grandes quantidades de dados existentes.
O aprendizado de máquina acrescenta outra nova dimensão à inteligência artificial: permite que os computadores aprendam ou se treinem a partir de grandes quantidades de dados existentes. Neste contexto, “aprender” significa extrair padrões de um determinado conjunto de dados. Pense em como funciona a nossa própria inteligência humana. Quando nos deparamos com algo desconhecido, usamos nossos sentidos para estudar suas características e depois as guardamos na memória para que possamos reconhecê-lo na próxima vez.
Como funciona o aprendizado de máquina (machine learning)?

O aprendizado de máquina envolve duas fases distintas: treinamento e inferência .
- Treinamento : no estágio de treinamento, um algoritmo de computador analisa um conjunto de amostras ou dados de treinamento para extrair recursos e padrões relevantes. Os dados podem ser qualquer coisa – números, imagens, texto e até fala.
- Inferência : a saída de um algoritmo de aprendizado de máquina (machine learning) é frequentemente chamada de modelo. Você pode pensar nos modelos de ML como dicionários ou manuais de referência, pois são usados para previsões futuras. Em outras palavras, usamos modelos treinados para inferir ou prever resultados de novos dados que nosso programa nunca viu antes.
O sucesso de um projeto de aprendizado de máquina depende de três fatores: o algoritmo em si, a quantidade de dados que você alimenta e a qualidade do conjunto de dados. De vez em quando, os pesquisadores propõem novos algoritmos ou técnicas que melhoram a precisão e reduzem erros, como veremos em uma seção posterior. Mas mesmo sem novos algoritmos, aumentar a quantidade de dados também ajudará a cobrir mais casos extremos e a melhorar a inferência.
Os programas de aprendizado de máquina envolvem duas etapas distintas: treinamento e inferência.
O processo de treinamento geralmente envolve a análise de milhares ou até milhões de amostras. Como seria de esperar, este é um processo bastante intensivo em hardware que precisa ser concluído com antecedência. No entanto, uma vez concluído o processo de treinamento e analisados todos os recursos relevantes, alguns modelos resultantes podem ser pequenos o suficiente para caber em dispositivos comuns, como smartphones.
Considere um aplicativo de aprendizado de máquina que lê texto manuscrito como o Google Lens , por exemplo. Como parte do processo de treinamento, um desenvolvedor primeiro alimenta um algoritmo de ML com imagens de amostra. Isso eventualmente lhes dá um modelo de ML que pode ser empacotado e implantado em algo como um aplicativo Android.
Quando os usuários instalam o aplicativo e o alimentam com imagens, seus dispositivos não precisam realizar o treinamento intensivo de hardware. O aplicativo pode simplesmente fazer referência ao modelo treinado para inferir novos resultados. No mundo real, você não verá nada disso, é claro – o aplicativo simplesmente converterá palavras manuscritas em texto digital.
Treinar um modelo de aprendizado de máquina é uma tarefa que exige muito hardware e pode levar várias horas ou até dias.
Por enquanto, aqui está um resumo das várias técnicas de treinamento de aprendizado de máquina e como elas diferem umas das outras.
Tipos de aprendizado de máquina: supervisionado, não supervisionado, reforço


Ao treinar um modelo de aprendizado de máquina, você pode usar dois tipos de conjuntos de dados: rotulados e não rotulados.
Pegue um modelo que identifique imagens de cães e gatos, por exemplo. Se você alimentar o algoritmo com imagens rotuladas dos dois animais, será um conjunto de dados rotulado. No entanto, se você espera que o algoritmo descubra sozinho os recursos de diferenciação (ou seja, sem rótulos indicando que a imagem contém um cachorro ou um gato), ele se tornará um conjunto sem rótulo. Dependendo do seu conjunto de dados, você pode usar abordagens diferentes para aprendizado de máquina:
- Aprendizagem supervisionada : Na aprendizagem supervisionada, usamos um conjunto de dados rotulado para ajudar o algoritmo de treinamento a saber o que procurar.
- Aprendizagem não supervisionada : se você estiver lidando com um conjunto de dados não rotulado, basta permitir que o algoritmo tire suas próprias conclusões. Novos dados são constantemente realimentados no sistema para treinamento – sem qualquer intervenção manual necessária de um ser humano.
- Aprendizagem por reforço : A aprendizagem por reforço funciona bem quando você tem muitas maneiras de atingir uma meta. É um sistema de tentativa e erro – as ações positivas são recompensadas, enquanto as negativas são descartadas. Isso significa que o modelo pode evoluir com base em suas próprias experiências ao longo do tempo.
Um jogo de xadrez é a aplicação perfeita para aprendizagem por reforço porque o algoritmo pode aprender com seus erros. Na verdade, a subsidiária DeepMind do Google desenvolveu um programa de ML que usava aprendizado por reforço para se tornar melhor no jogo de tabuleiro Go. Entre 2016 e 2017 , derrotou vários campeões mundiais de Go em ambientes competitivos – uma conquista notável, para dizer o mínimo.
Quanto ao aprendizado não supervisionado, digamos que um site de comércio eletrônico como o Amazon queira criar uma campanha de marketing direcionada. Normalmente, eles já sabem muito sobre seus clientes, incluindo idade, histórico de compras, hábitos de navegação, localização e muito mais. Um algoritmo de aprendizado de máquina seria capaz de formar relacionamentos entre essas variáveis. Pode ajudar os profissionais de marketing a perceber que os clientes de uma determinada área tendem a comprar certos tipos de roupas. Seja qual for o caso, é um processo de processamento de números totalmente automático.
Para que é usado o aprendizado de máquina? Exemplos e vantagens


Aqui estão algumas maneiras pelas quais o aprendizado de máquina influencia nossas vidas digitais:
- Reconhecimento facial : até mesmo recursos comuns de smartphones, como reconhecimento facial, dependem de aprendizado de máquina. Veja o aplicativo Google Fotos como outro exemplo. Ele não apenas detecta rostos em suas fotos, mas também usa aprendizado de máquina para identificar características faciais exclusivas de cada indivíduo. As imagens que você carrega ajudam a melhorar o sistema, permitindo fazer previsões mais precisas no futuro. O aplicativo também solicita frequentemente que você verifique se uma determinada correspondência é precisa – indicando que o sistema tem um baixo nível de confiança nessa previsão específica.
- Fotografia computacional : há mais de meia década, os smartphones usam aprendizado de máquina para aprimorar imagens e vídeos além das capacidades do hardware. Do impressionante empilhamento HDR à remoção de objetos indesejados, a fotografia computacional se tornou um dos pilares dos smartphones modernos.
- Chatbots de IA : se você já usou ChatGPT ou Bing Chat , já experimentou o poder do aprendizado de máquina por meio de modelos de linguagem. Esses chatbots foram treinados em bilhões de amostras de texto. Isso permite que eles entendam e respondam às dúvidas dos usuários em tempo real. Eles também têm a capacidade de aprender com suas interações, melhorando suas respostas futuras e tornando-se mais eficazes ao longo do tempo.
- Recomendações de conteúdo : plataformas de mídia social como o Instagram mostram anúncios direcionados com base nas postagens com as quais você interage. Se você gosta de uma imagem contendo comida, por exemplo, poderá receber anúncios relacionados a kits de refeição ou restaurantes próximos. Da mesma forma, serviços de streaming como YouTube e Netflix podem inferir novos gêneros e tópicos de seu interesse, com base em seu histórico de exibição e duração.
- Aprimoramento de fotos e vídeos : O DLSS da NVIDIA é um grande negócio na indústria de jogos, onde ajuda a melhorar a qualidade da imagem por meio do aprendizado de máquina. A forma como o DLSS funciona é bastante direta: primeiro uma imagem é gerada em uma resolução mais baixa e, em seguida, um modelo de ML pré-treinado ajuda a aumentá-la. Os resultados são impressionantes, para dizer o mínimo – muito melhores do que as tecnologias tradicionais de upscaling não-ML.
Desvantagens do aprendizado de máquina
O aprendizado de máquina visa alcançar uma precisão razoavelmente alta com o mínimo de esforço e tempo. Nem sempre é bem-sucedido, é claro.
Em 2016, a Microsoft revelou um chatbot de última geração chamado Tay. Como demonstração de suas habilidades de conversação semelhantes às humanas, a empresa permitiu que Tay interagisse com o público por meio de uma conta no Twitter. No entanto, o projeto foi colocado offline apenas 24 horas depois que o bot começou a responder com comentários depreciativos e outros diálogos inadequados. Isso destaca um ponto importante: o aprendizado de máquina só é realmente útil se os dados de treinamento forem de qualidade razoavelmente alta e estiverem alinhados com seu objetivo final. Tay foi treinado em envios ao vivo no Twitter, o que significa que foi facilmente manipulado ou treinado por atores mal-intencionados.
O aprendizado de máquina não é um arranjo único para todos. Requer um planejamento cuidadoso, um conjunto de dados variado e limpo e supervisão ocasional.
Nesse sentido, o preconceito é outra desvantagem potencial do aprendizado de máquina. Se o conjunto de dados usado para treinar um modelo for limitado em seu escopo, poderá produzir resultados que discriminem determinados setores da população. Por exemplo, a Harvard Business Review destacou como uma IA tendenciosa pode ter maior probabilidade de escolher candidatos a empregos de uma determinada raça ou sexo.
Termos comuns de aprendizado de máquina: um glossário

Se você leu algum outro recurso sobre aprendizado de máquina, é provável que tenha se deparado com alguns termos confusos. Então, aqui está um rápido resumo das palavras mais comuns relacionadas ao ML e o que elas significam:
- Classificação : Na aprendizagem supervisionada, a classificação refere-se ao processo de análise de um conjunto de dados rotulado para fazer previsões futuras. Um exemplo de classificação seria separar e-mails de spam dos legítimos.
- Clustering : Clustering é um tipo de aprendizado não supervisionado, onde o algoritmo encontra padrões sem depender de um conjunto de dados rotulado. Em seguida, ele agrupa pontos de dados semelhantes em grupos diferentes. A Netflix, por exemplo, usa clustering para prever se você provavelmente gostará de um programa.
- Overfitting : se um modelo aprender muito bem com seus dados de treinamento, ele poderá ter um desempenho ruim quando testado com pontos de dados novos e invisíveis. Isso é conhecido como sobreajuste. Por exemplo, se você treinar um modelo apenas com imagens de uma espécie específica de banana, ele não reconhecerá uma que não tenha visto antes.
- Época : quando um algoritmo de aprendizado de máquina analisa seu conjunto de dados de treinamento uma vez, chamamos isso de época única. Portanto, se revisarmos os dados de treinamento cinco vezes, podemos dizer que o modelo foi treinado por cinco épocas.
- Regularização : um engenheiro de aprendizado de máquina pode adicionar uma penalidade ao processo de treinamento para que o modelo não aprenda os dados de treinamento com muita perfeição. Essa técnica, conhecida como regularização, evita overfitting e ajuda o modelo a fazer melhores previsões para dados novos e não vistos.
Além desses termos, você também deve ter ouvido falar em redes neurais e aprendizado profundo. Porém, eles são um pouco mais complicados, então vamos falar sobre eles com mais detalhes.
Aprendizado de máquina versus redes neurais versus aprendizado profundo

Uma rede neural é um subtipo específico de aprendizado de máquina inspirado no comportamento do cérebro humano. Os neurônios biológicos no corpo de um animal são responsáveis pelo processamento sensorial. Eles coletam informações do ambiente e transmitem sinais elétricos por longas distâncias até o cérebro. Nossos corpos têm bilhões desses neurônios que se comunicam entre si, ajudando-nos a ver, sentir, ouvir e tudo mais.
Uma rede neural imita o comportamento dos neurônios biológicos no corpo de um animal.
Nesse sentido, os neurônios artificiais em uma rede neural também conversam entre si. Eles dividem problemas complexos em pedaços menores ou “camadas”. Cada camada é composta de neurônios (também chamados de nós) que realizam uma tarefa específica e comunicam seus resultados aos nós da próxima camada. Em uma rede neural treinada para reconhecer objetos, por exemplo, você terá uma camada com neurônios que detectam bordas, outra que observa mudanças de cor e assim por diante.
As camadas estão interligadas, portanto, “ativar” uma cadeia específica de neurônios fornece uma certa saída previsível. Devido a esta abordagem multicamadas, as redes neurais são excelentes na resolução de problemas complexos. Considere veículos autônomos ou autônomos, por exemplo. Eles usam uma infinidade de sensores e câmeras para detectar estradas, sinalização, pedestres e obstáculos. Todas essas variáveis têm algum relacionamento complexo entre si, tornando-as uma aplicação perfeita para uma rede neural multicamadas.
Aprendizado profundo é um termo frequentemente usado para descrever uma rede neural com muitas camadas. O termo “profundo” aqui refere-se simplesmente à profundidade da camada.
Hardware de aprendizado de máquina: como funciona o treinamento?

Muitos dos aplicativos de aprendizado de máquina mencionados acima, incluindo reconhecimento facial e aumento de escala de imagem baseado em ML, já foram impossíveis de serem realizados em hardware de consumo. Em outras palavras, você precisava se conectar a um servidor poderoso localizado em um data center para realizar a maioria das tarefas relacionadas ao ML.
Ainda hoje, treinar um modelo de ML exige muito hardware e praticamente requer hardware dedicado para projetos maiores. Como o treinamento envolve a execução repetida de um pequeno número de algoritmos, os fabricantes geralmente projetam chips personalizados para obter melhor desempenho e eficiência. Eles são chamados de circuitos integrados de aplicação específica ou ASICs. Projetos de ML em grande escala normalmente usam ASICs ou GPUs para treinamento, e não CPUs de uso geral. Eles oferecem maior desempenho e menor consumo de energia do que uma CPU tradicional.
Os aceleradores de aprendizado de máquina ajudam a melhorar a eficiência da inferência, possibilitando a implantação de aplicativos de ML em cada vez mais dispositivos.
As coisas começaram a mudar, no entanto, pelo menos no lado da inferência. O aprendizado de máquina no dispositivo está começando a se tornar mais comum em dispositivos como smartphones e laptops. Isso se deve à inclusão de aceleradores de ML dedicados em nível de hardware em processadores e SoCs modernos.
Os aceleradores de aprendizado de máquina são mais eficientes que os processadores comuns. É por isso que a tecnologia de upscaling DLSS de que falamos anteriormente, por exemplo, só está disponível em placas gráficas NVIDIA mais recentes com hardware de aceleração de ML. No futuro, provavelmente veremos segmentação e exclusividade de recursos dependendo dos recursos de aceleração de aprendizado de máquina de cada nova geração de hardware. Na verdade, já estamos testemunhando isso acontecer na indústria de smartphones.
Aprendizado de máquina em smartphones
![]()
Os aceleradores de ML já foram integrados aos SoCs dos smartphones há algum tempo. E agora, eles se tornaram um ponto focal importante graças à fotografia computacional e ao reconhecimento de voz.
Em 2021, o Google anunciou seu primeiro SoC semipersonalizado, apelidado de Tensor, para o Pixel 6 . Um dos principais diferenciais do Tensor era seu TPU personalizado – ou Tensor Processing Unit. O Google afirma que seu chip oferece inferência de ML significativamente mais rápida em comparação à concorrência, especialmente em áreas como processamento de linguagem natural. Isso, por sua vez, possibilitou novos recursos, como tradução de idiomas em tempo real e funcionalidade de conversão de fala em texto mais rápida. Os processadores de smartphones da MediaTek, Qualcomm e Samsung também têm suas próprias versões de hardware de ML dedicado.
O aprendizado de máquina no dispositivo possibilitou recursos futuristas, como tradução em tempo real e legendas ao vivo.
Isso não quer dizer que a inferência baseada em nuvem ainda não seja usada hoje – muito pelo contrário, na verdade. Embora o aprendizado de máquina no dispositivo tenha se tornado cada vez mais comum, ainda está longe do ideal. Isto é especialmente verdadeiro para problemas complexos como reconhecimento de voz e classificação de imagens. Assistentes de voz como Alexa da Amazon e Google Assistant são tão bons quanto são hoje porque contam com uma poderosa infraestrutura em nuvem – tanto para inferência quanto para retreinamento de modelos.
No entanto, tal como acontece com a maioria das novas tecnologias, novas soluções e técnicas estão constantemente no horizonte. Em 2017, o algoritmo HDRnet do Google revolucionou a imagem de smartphones, enquanto o MobileNet reduziu o tamanho dos modelos de ML e tornou viável a inferência no dispositivo. Mais recentemente, a empresa destacou como utiliza uma técnica de preservação de privacidade chamada aprendizagem federada para treinar modelos de aprendizagem de máquina com dados gerados pelo utilizador.
Enquanto isso, a Apple também integra aceleradores de hardware ML em todos os seus chips de consumo atualmente. A família de SoCs Apple M1 e M2 incluída nos Macbooks mais recentes, por exemplo, possui capacidade de aprendizado de máquina suficiente para realizar tarefas de treinamento no próprio dispositivo.
Artigos Relacionados





0 Comentários